在跑完 OLS 之後,我們常會抓出係數的標準誤 (standard error),以及計算其對應之 t 值。在 statsmodels 套件中的標準誤函數是 .bse(),它也是向量,其讀取的語法和 .params() 是一樣的。而計算第 i 個迴歸係數的 t 值的公式是:

其中 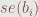

跑 OLS 後進行預測
步驟
- 先跑迴歸方程式
- 抓估計係數
- 以 Y0 值代入
預測 C0

此程式會用到的模組和函數
- pandas
- .read_csv(‘檔名’, [指標欄=n])
用來讀 csv 檔
- .read_csv(‘檔名’, [指標欄=n])
- statsmodels.formula.api
- .ols(eq, df)
定義 OLS 迴歸和資料來源 - .ols(eq, df).fit()
執行 OLS 和回傳結果到 result1 - .params[n]
置放 OLS 估計參數的向量,向量指標編號從 0 開始,.params[0] 是常數項 - .bse[n]
置放 OLS 估計參數的標準誤之向量,同樣向量指標編號從 0 開始,.bse[0] 是常數項的標準誤 - .tvalues[n]
置放 OLS 估計參數的標準誤之 t 值,一樣向量指標編號從 0 開始,.tvalues[0] 是常數項的標準誤
- .ols(eq, df)
- print()
- 這是 Python 的列印輸出函數。這裡的語法先簡要說明:
- 它可以像以下的範例程式 Code 1.3 的第12、15行,直接將要輸出的字串放在小括號內。
- 而另一個的語法,如14、16行所示,print(‘%f, %f’ % (x1,x2)),小括號內的第 1 個參數是字串 ‘%f, %f’,% 符號是必要的,後面跟著 f 代表輸出的是「浮點數」格式 (就是有小數點的數);此字串中有兩個 %f,表示後面有兩個以小括號「框住」的數字 x1, x2 會被以「浮點數」格式列印輸出;。print() 還有更多詳細的語法,可參考另外一篇 Python:輸出格式化 print()。
程式說明
- 第2-4行,將 data3-6.csv 資料檔讀進別名為 data 的資料結構
- 第5行,匯入 statsmodels.formula.api 並命別名為 smf
- 第7行,定義迴歸模型字串
eq = 'Ct~Yt' - 第8行,依迴歸模型和資料執行 OLS ,並將結果回傳到 result1
(註:此次我們示範也可以不用像 code 1.3 使用 model1,直接將結果像 result1=smf.ols(eq,data).fit() 這樣,回傳到 result1) - 第10行,將 result1.params[n] (n = 1, 2) 中的數據,分別放在 b1, b2 當中
- 第11行,將 result1.tvalues[n] (n = 1, 2) 中的數據,分別放在 stderr1, stderr2 當中
- 第12、15行,列印註解說明的文字
- 第13行,依 t 值公式,計算出估計的常數項和係數的 t 值
- 第14、16行,以 ‘t1=%f, t2=%f" 的格式,輸出常數項和係數的 t 值
- 第16行,用 result1.tvalues[0] 和 result1.tvalues[1] 取出 statsmodels 所提供的 t 值
Colab Python 程式碼
# Code 1.3: 計算係數之 t 值
import pandas as pd
path='https://github.com/powebe/p4econ/raw/main/'
data=pd.read_csv(path+'data3-6.csv',index_col=0)
import statsmodels.formula.api as smf
# ols: Ct = b1 +b2*Yt
eq = 'Ct~Yt'
result1=smf.ols(eq,data).fit()
# --- 抓係數,將 result1.params[0],result1.params[1] 中的數據,分別放在 b1, b2 當中
b1, b2 = result1.params[0],result1.params[1]
stderr1, stderr2 = result1.bse[0],result1.bse[1]
print('---自行計算係數之 t 值---')
t_b1, t_b2 = b1/stderr1,b2/stderr2
print('t_b1=%f, t_b2=%f'% (t_b1, t_b2))
print('---從 statsmodels 模組抓係數 t 值---')
print('t1=%f, t2=%f' % (result1.tvalues[0],result1.tvalues[1]))
Colab 操作
在用 google 帳號登入 colab 後,可以用 [/檔案/新增筆記本] 來創建 python 環境
將上面的程式碼複製後,用 [ctrl]+[v] 貼上,最後按播放鈕來執行。
Colab 執行結果
如圖最下方所示,我們自行計算的,和從模組抓的 t 值是一樣的。

