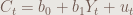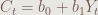財務計量 開源 gretl | 2021年版

即日~2023年2月28日止
登入7-11賣場
輸入折扣碼: 88881688
本站網友獨享折扣:9 折
2023年 2/1~2/28 運費再享優惠35元
好消息!!(2024/05/01)前成立之訂單,運費仍維持35元喔。

https://fred.stlouisfed.org/graph/?g=12Onu
![]()
https://fred.stlouisfed.org/graph/?g=12NN6
分開應變數、自變數 (常數項要外加)
https://www.statsmodels.org/stable/api.html#statsmodels-api
import statsmodels.api as sm y = df1 x = df2 # 在 x 這個 pd 中加入一行常數 1 x['const']=1 #fit regression model model = sm.OLS(y, x).fit()
用字串設定迴歸式
應變數、自變數放在一個 dataframe (常數項自動加)
https://www.statsmodels.org/stable/api.html#statsmodels-formula-api
import statsmodels.formula.api as smf # 設定迴歸方程式:t = b1 + b2*x # 以字串形式放在 eq 文字變數中 eq = 'y~x' model1=smf.ols(eq,df) result1=model1.fit() # 印出迴歸估計結果 print(result1.summary())
自我相關函數、偏自我相關函數 acf, pacf
(https://www.statsmodels.org/stable/api.html)
import statsmodels.tsa.api as smt acf, q, pval = smt.acf(_Y, nlags=20, qstat=True,fft=False) pacf=smt.acf(_Y,nlags=20)
nlag=20
ts_correl=pd.DataFrame({'LAG':range(1,nlag+1),'acf':acf[1:],'pacf':pacf[1:],'Q':q,'p-val':pval},index=range(1,nlag+1))
import statsmodels.stats.diagnostic as <strong>ssd</strong> # 定義White's test 輸出欄名稱 rname = ['Test Statistic', 'Test Statistic p-value', 'F-Statistic', 'F-Test p-value'] # 進行 White's test White = pd.DataFrame(<strong>ssd</strong>.het_white(model.resid, model.model.exog), index=rname) White.columns = ['White-Test'] print(White[:2].round(4)) #只印前兩個 row
DataFrame 是 Pandas 套件的一個非常重要的資料結構,常見於各種資料分析方法,特別是時間序列分析方法。若用 pandas_datareader 或 yfinance 抓股市日資料,抓回來的資料,也是存放於 dataframe 的資料結構之中。例如,結合 pandas 和 pandas datareader 套件,抓 yahoo finance 資料,datareader 回傳的就是 DataFrame 的資料 (見以下程式碼)。
我們可以將 dataframe 視為是像 excel 的「表格式資料」,包今有列、欄… 的多維資料集。
用 pd.DataFrame(資料, 欄位標題),例如,用 np.random.normal(size=(500,3)) 產生 3欄 500 筆「隨機常態分配」資料,然後分別命名為 time、X、Y 為欄位名稱。
import pandas as pd df=pd.DataFrame(np.random.normal(size=(500,3)),columns=['time','X','Y'])
用雙中括號 [[‘欄位名1’,’欄位名1’…]]
df2 = df[['a','b1','b2']]從 data 取出部份欄位資料 data[[‘A1′,’A2’]],放進另一個 df2,並將新欄位名稱重新命名為 r1、r2,語法,注意要用大括號 {} 包覆:
df2= pd.DataFrame({‘r1’: data[‘A1’]), ‘r2’: data[‘A2’]})
df = pd.DataFrame({'r_aapl': ldiff(data['Close']['AAPL']),
'r_tsla': ldiff(data['Close']['TSLA'])})DataFrame.diff(periods=1, axis=0),例如
# X 是 dataframe
dX = X.diff()會輸出樣本數、平均數、標準差、最大最小值等敘述統計。
DataFrame.describe()
r_aapl r_sp500
count 47.000000 47.000000
mean 3.074668 1.113741
std 9.010071 4.976879
min -20.339557 -13.366772
25% -2.567104 -0.978388
50% 5.490090 2.022584
75% 9.340332 3.750472
max 19.423344 11.942084
參數說明如下:
名稱.DataReader(‘股票代碼’, data_source=’資料來源’, start=’開始日字串’, end=’結束日字串’)
股票代碼可以是字串、陣列 (array-like object, 含 list, tuple, Series, or DataFrame) 可查:https://gretlcycu.wordpress.com/2013/08/07/yahoo-finance-%e7%9a%84-ticker-symbol/
其它參數 see原始文件:https://pandas-datareader.readthedocs.io/en/latest/readers/yahoo.html
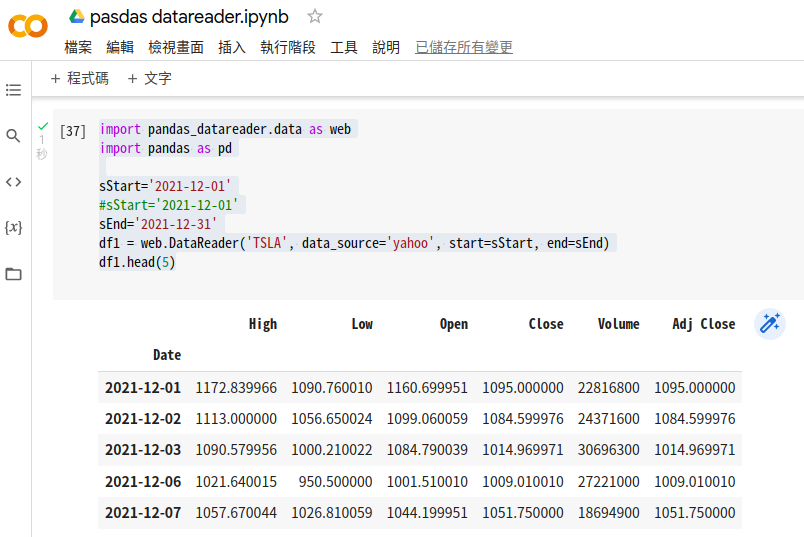
import pandas_datareader.data as web
import pandas as pd
# 用字串定義開始、截止日
sStart='2021-12-01'
sEnd='2021-12-31'
df1 = web.DataReader('TSLA', data_source='yahoo', start=sStart, end=sEnd)
df1.head(5)
或者抓多種股價
# 抓多個股票資料 stocks = ['AAPL','TSLA'] df2 = web.DataReader(stocks, data_source='yahoo', start=sStart, end=sEnd) df2.head(5)


想要在 python 中顯示數據時,指定數字的小數位數,例如,小數點後兩位,在套件 pandas 中的類別 dataframe 可以使用 .round(N) 來指定;N 為小數點後 N 位。
# !pip install yfinance
import pandas as pd
import yfinance as yf
# --- 讀Tesla 股市資料
TSLA = yf.download("TSLA", interval = "1mo", start="2021-07-01", end="2021-12-31")
# --- 不指定 小數點位數
print(TSLA)
# --- 指定 小數點後 2 位數
print('---> 以下指定 小數點後 2 位數')
print(TSLA.round(2))
在 colab 中,按 ctrl+enter 看執行結果:


在跑完 OLS 之後,我們常會抓出係數的標準誤 (standard error),以及計算其對應之 t 值。在 statsmodels 套件中的標準誤函數是 .bse(),它也是向量,其讀取的語法和 .params() 是一樣的。而計算第 i 個迴歸係數的 t 值的公式是:

其中 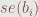

步驟

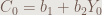 預測 C0
預測 C0此程式會用到的模組和函數
程式說明
eq = 'Ct~Yt'
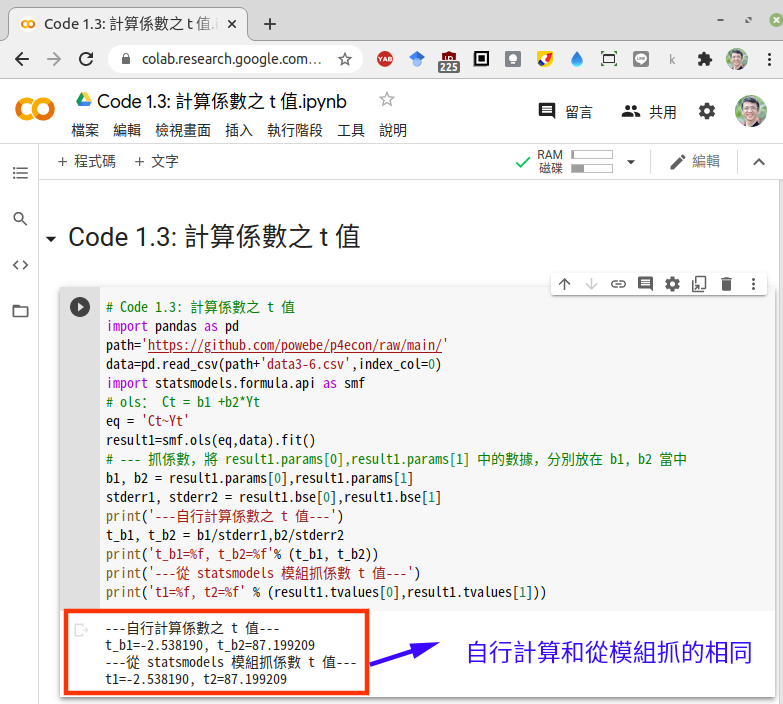
# Code 1.3: 計算係數之 t 值
import pandas as pd
path='https://github.com/powebe/p4econ/raw/main/'
data=pd.read_csv(path+'data3-6.csv',index_col=0)
import statsmodels.formula.api as smf
# ols: Ct = b1 +b2*Yt
eq = 'Ct~Yt'
result1=smf.ols(eq,data).fit()
# --- 抓係數,將 result1.params[0],result1.params[1] 中的數據,分別放在 b1, b2 當中
b1, b2 = result1.params[0],result1.params[1]
stderr1, stderr2 = result1.bse[0],result1.bse[1]
print('---自行計算係數之 t 值---')
t_b1, t_b2 = b1/stderr1,b2/stderr2
print('t_b1=%f, t_b2=%f'% (t_b1, t_b2))
print('---從 statsmodels 模組抓係數 t 值---')
print('t1=%f, t2=%f' % (result1.tvalues[0],result1.tvalues[1]))
在用 google 帳號登入 colab 後,可以用 [/檔案/新增筆記本] 來創建 python 環境
將上面的程式碼複製後,用 [ctrl]+[v] 貼上,最後按播放鈕來執行。
如圖最下方所示,我們自行計算的,和從模組抓的 t 值是一樣的。
以下介紹如何用程式抓取 OLS 模型所估計的參數,並利用它們來進行預測。先看以下的程式
步驟
預測 C0此程式會用到的模組和函數
程式說明
eq = 'Ct~Yt'# Code 1.2: OLS 模型之預測 import pandas as pd path='https://github.com/powebe/p4econ/raw/main/' data=pd.read_csv(path+'data3-6.csv',index_col=0) import statsmodels.formula.api as smf # ols: Ct = b1 +b2*Yt eq = 'Ct~Yt' model1=smf.ols(eq,data) result1=model1.fit() # 將 result1.params[0],result1.params[1] 中的數據,分別放在 b1, b2 當中 b1, b2 =result1.params[0],result1.params[1] # --- 進行預測 Y0 = 12000 C0 = b1 + b2*Y0 print(C0)
在用 google 帳號登入 colab 後,可以用 [/檔案/新增筆記本] 來創建 python 環境
將上面的程式碼複製後,用 [ctrl]+[v] 貼上,最後按播放鈕來執行。

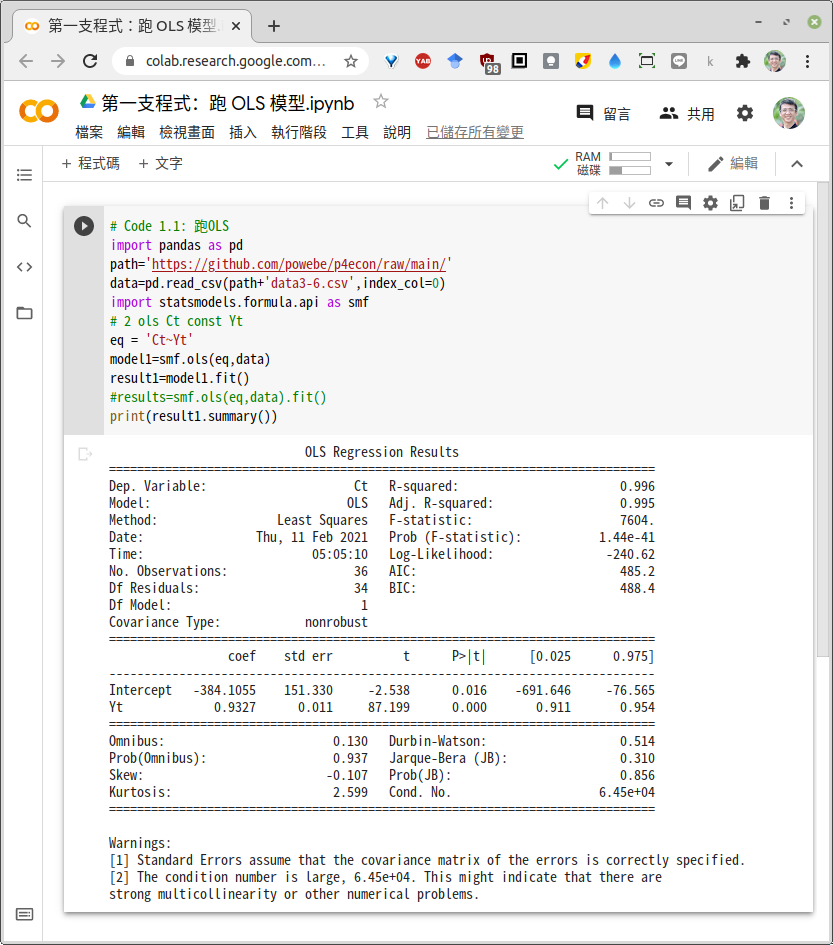
以下是我們介紹給初學者的第一支程式。這支程式的任務很單純,第1部份是開啟資料檔,而第2部份是執行 OLS 模型之估計。
這個OLS模型叫做簡單迴歸,其迴歸方程式是:
其中 


這條迴歸方程式主要是估計總體經濟學創立者凱因斯提出的「消費方程式」1。以下則是示範在 Python 中跑此迴歸方程式的程式碼。
# Code 1.1: 跑OLS (以 # 開頭的是註解行,不會被執行) import pandas as pd path='https://github.com/powebe/p4econ/raw/main/' data=pd.read_csv(path+'data3-6.csv',index_col=0) import statsmodels.formula.api as smf # 2 ols Ct const Yt eq = 'Ct~Yt' model1=smf.ols(eq,data) result1=model1.fit() print(result1.summary())
在用 google 帳號登入 colab 後,可以用 [/檔案/新增筆記本] 來創建 python 環境

將上面的程式碼複製後,用 [ctrl]+[v] 貼上

最後按播放鈕來執行。